4. ANOVA analysis (introduction)¶
Although we provide a Standalone application called gdsctools_anova, the most up-to-date and flexible way of using GDSCTools is to use the library from an IPython shell. This method (using IPython shell) is also the only way to produce Data Packages.
In this section we will exclusively use Python commands, which should also be of interest if you want to look at the Notebooks section later.
We assume now that (i) you have GDSCtools installed together with IPython. If not, please go back to the Installation section. (ii) you are familiar with the INPUT data sets that will be used hereafter.
Note
Beginners usually enter in an Python shell (typing python). Instead, we strongly recommend to use IPython, which is a more flexible and interactive shell. To start IPython, just type this command in a terminal:
ipython
You should now see something like:
Python 2.7.5 (default, Nov 3 2014, 14:33:39)
Type "copyright", "credits" or "license" for more information.
IPython 4.0.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]:
Note
All snippets in this documentation are typed within IPython shell. You may see >>> signs. They indicate a python statement typed in a shell. Lines without those signs indicate the output of the previous statement. For instance:
>>> a = 3
>>> 2 + a
5
means the code 2 + a should print the value 5
4.1. The IC50 input data¶
Before starting, we first need to get an IC50 data set example. Let us use this
IC50 example test file.
See also
More details about the data format can be found in the Data Format and Readers section as well as links to retrieve IC50 data sets.
In Python, one can easily import all functionalities available in GDSCTools as follows:
from gdsctools import *
Although this syntax is correct, in the following we will try to be more explicit. So, we would rather use:
from gdsctools import IC50
This is better coding practice and has also the advantage of telling beginners which functions are going to be used.
Here above, we imported the IC50 class that is required to read the example file aforementioned. Note that this IC50 example is installed with GDSCTools and its location can be obtained using:
from gdsctools import ic50_test
print(ic50_test.filename)
The IC50 class is flexible enough that you can provide the filename location or just the name ic50_test as in the example below, and of course the filename of a local file would work as well:
>>> from gdsctools import IC50, ic50_test
>>> ic = IC50(ic50_test)
>>> print(ic)
Number of drugs: 11
Number of cell lines: 988
Percentage of NA 0.206569746043
As you can see you can get some information about the IC50 content (e.g.,
number of drugs, percentage of NaNs) using the The print statement function. See gdsctools.readers.IC50 and Data Format and Readers for more details.
4.2. Getting help¶
At any time, you can get help about a GDSCTools functionality or a python function by adding question tag after a function’s name:
IC50?
With GDSCTools, we also provide a convenience function called gsdctools_help():
gdsctools_help(IC50)
that should open a new tab in a browser redirecting you to the HTML help version (on ReadTheDoc website) of a function or class (here the IC50 class).
4.3. The ANOVA class¶
One of the main application of GDSCTools is based on an ANOVA analysis that is used to identify significant associations between drug and genomic features. As mentionned above, a first file that contains the IC50s is required. That file contains experimentall measured IC50s for a set of 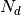 drugs across
drugs across 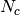 cell lines. The second data file is a binary file that contains various features across the same cell lines. Those
cell lines. The second data file is a binary file that contains various features across the same cell lines. Those 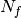 features are usually of genomic types (e.g., mutation, CNA, Methylation). A default set of about 50 genomic features is provided and automatically fetched in the following examples. You may also provide your own data set as an input.
features are usually of genomic types (e.g., mutation, CNA, Methylation). A default set of about 50 genomic features is provided and automatically fetched in the following examples. You may also provide your own data set as an input.
The default genomic feature file is downloadable and its location can be found using:
from gdsctools import datasets
gf = datasets.genomic_features
See also
More details about the genomic features data format can be found in the Data Format and Readers section.
The class of interest ANOVA takes as input a compulsary IC50
filename (or data) and possibly a genomic features filename (or data). Using
the previous IC50 test example, we can create an ANOVA instance as follows:
from gdsctools import ANOVA, ic50_test
an = ANOVA(ic50_test)
Again, note that the genomic features is not provided, so the default file aforementionned will be used except if you provide a specific genomic features file as the second argument:
an = ANOVA(ic50_test, "your_genomic_features.csv")
There are now several possible analysis but the core of the analysis consists
in taking One Drug and One Feature (ODOF hereafter) and to compute the
association using a regression analysis (see Regression analysis for details).
The IC50 across the cell lines being
the dependent variable 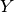 and the explanatory variables denoted
and the explanatory variables denoted 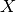 are made of tissues, MSI and one genomic feature. Following the regression analysis, we compute the ANOVA summary leading to a p-value for the significance of the association between the drug’s IC50s and the genomic feature considered. This calculation is performed with the
are made of tissues, MSI and one genomic feature. Following the regression analysis, we compute the ANOVA summary leading to a p-value for the significance of the association between the drug’s IC50s and the genomic feature considered. This calculation is performed with the anova_one_drug_one_feature() method.
We will see a concrete example in a minute. Once an ODOF is computed, one can
actually repeat the ODOF analysis for a given drug across all features using the anova_one_drug() method. This is also named One Drug All Feature case (ODAF). Finally we can even extend the analysis to All Drugs All Features (ADAF) using anova_all().
The following image illustrates how those 3 methods interweave together like Russian dolls.
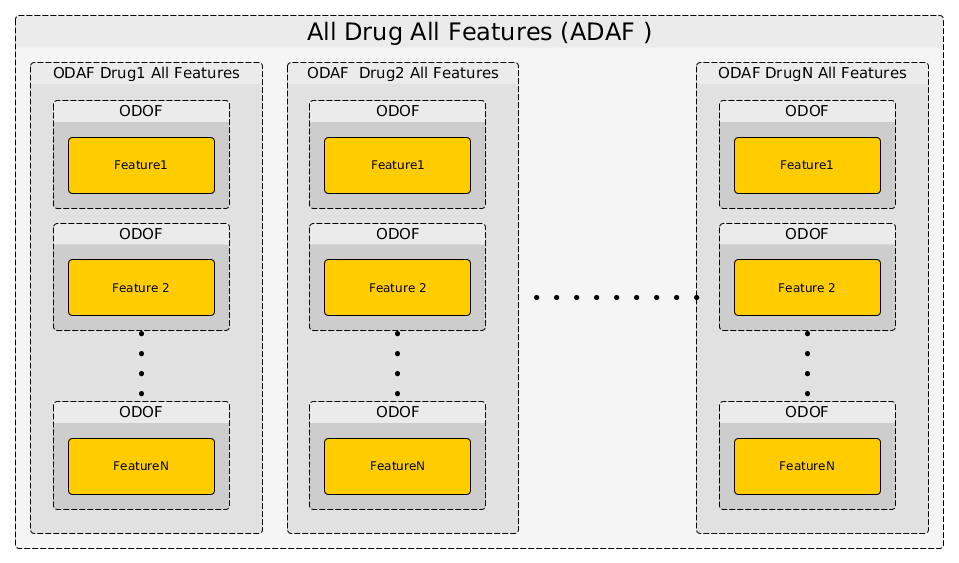
The computational time is therefore increasing with the number of drugs and features. Let us now perform the analysis for the 3 different cases.
4.3.1. One Drug One Feature (ODOF)¶
Let us start with the first case (ODOF). User needs to provide a drug and a feature name and to call the anova_one_drug_one_feature() method. Here is an example:
from gdsctools import ANOVA, ic50_test
gdsc = ANOVA(ic50_test)
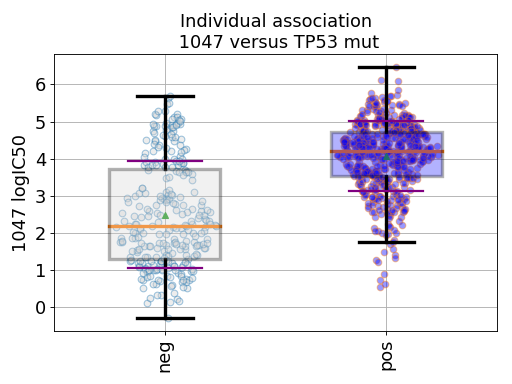
gdsc.anova_one_drug_one_feature(1047, 'TP53_mut', show=True, fontsize=16)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
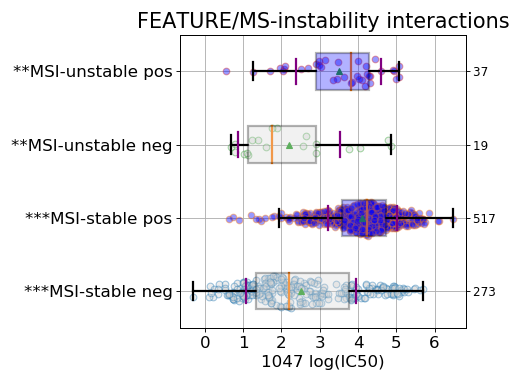
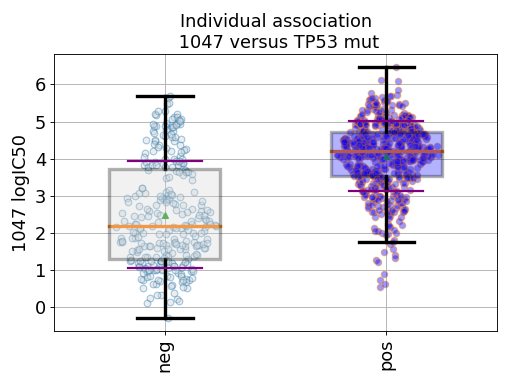
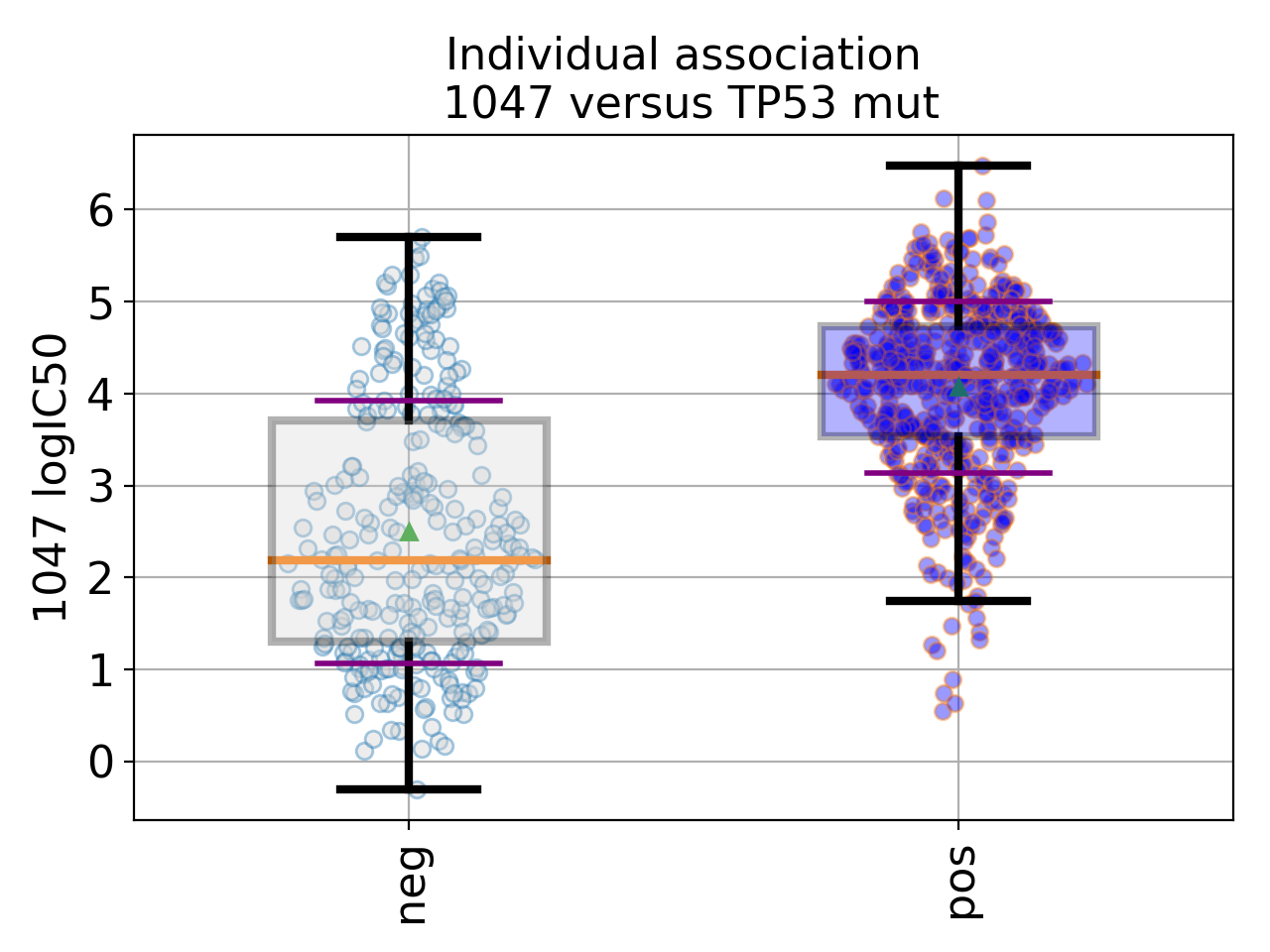
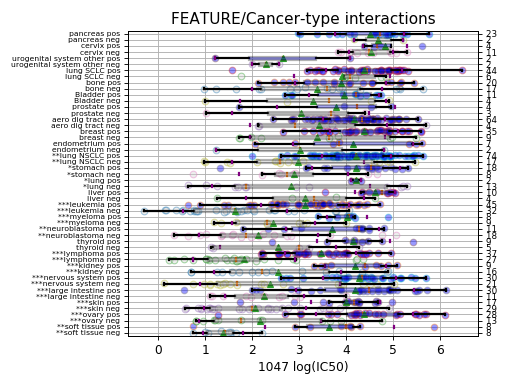
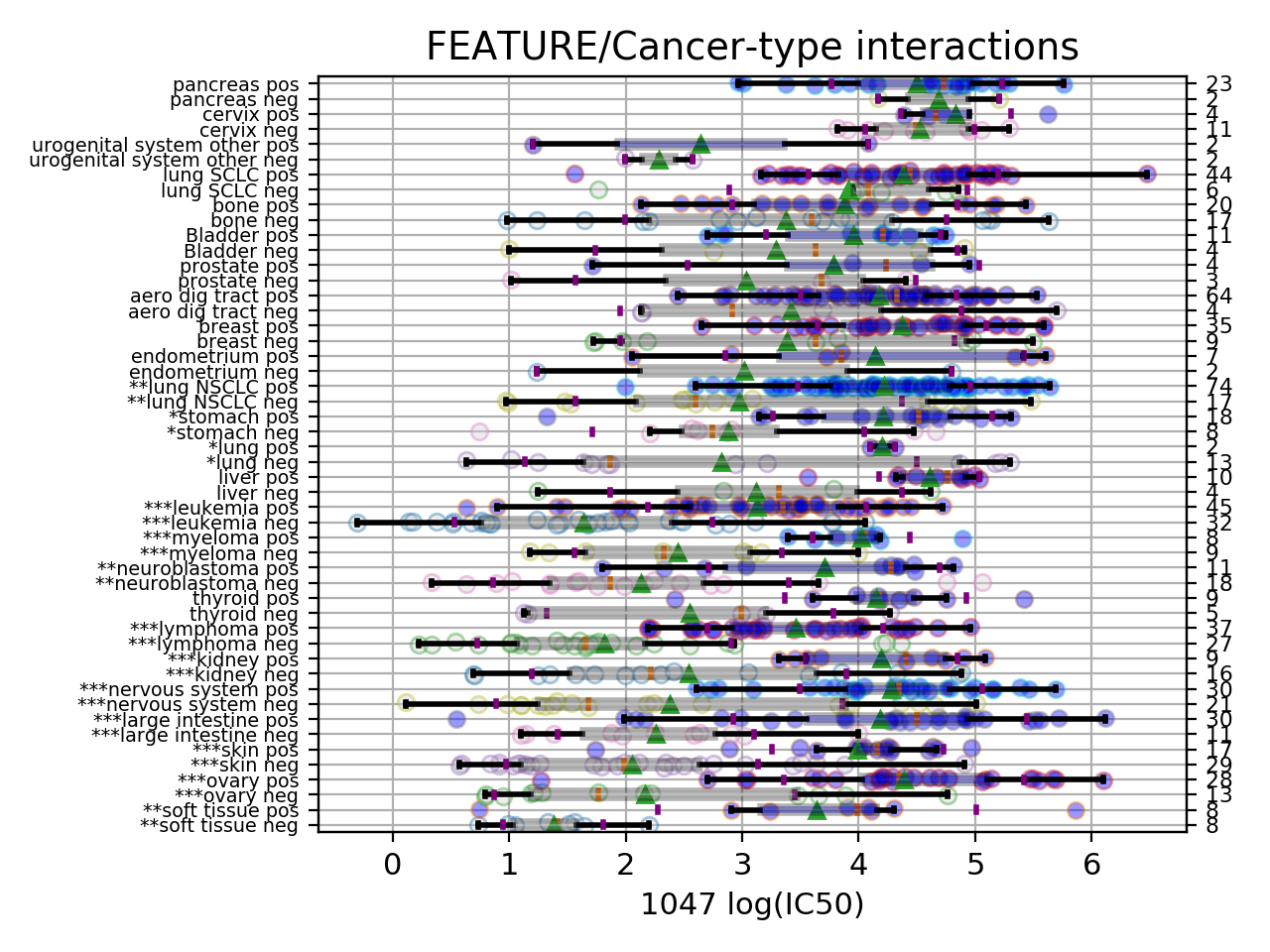
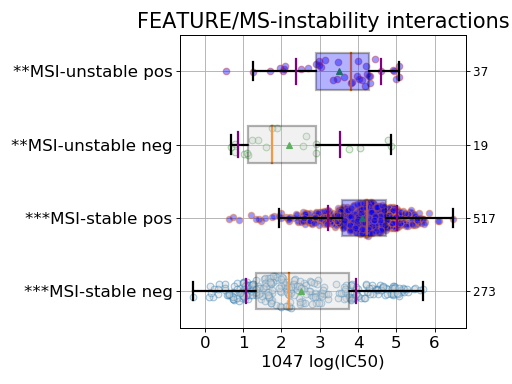
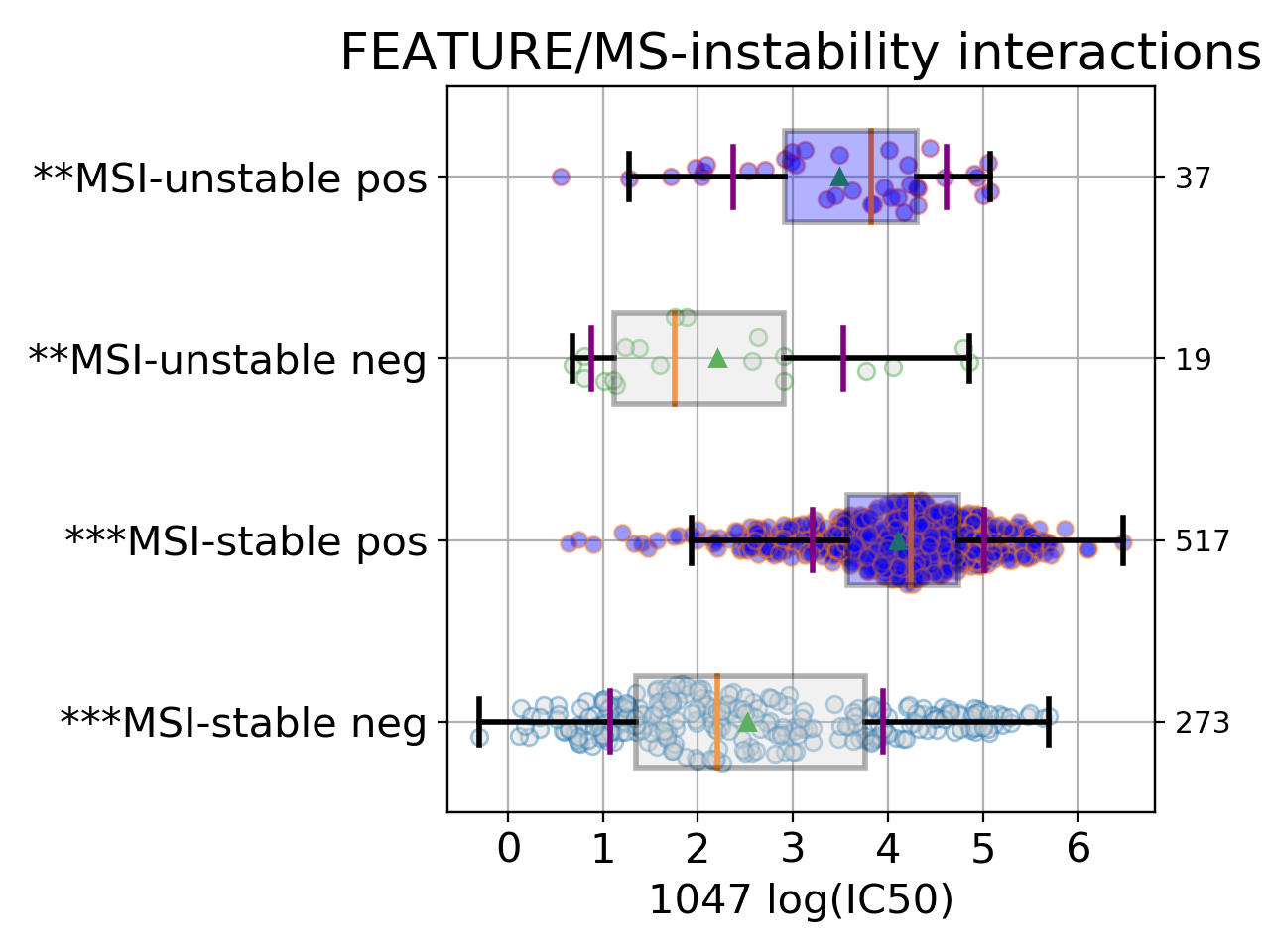
Setting the show parameter to True, we created a set of 3 boxplots that is one for each explanatory feature considered: tissue, MSI and genomic feature.
If there is only one tissue, this factor is included in the explanatory variable is not used (and the corresponding boxplot not produced). Similarly, the MSI factor may be ignored if irrelevant.
In the first boxplot, the feature factor is considered; we see the IC50s being divided in two populations (negative and positive features) where all tissues are mixed.
In the second boxplot, the tissue variable is explored; this is a decomposition of the first boxplot across tissues.
Finally, the third boxplot shows the impact of the MSI factor. Here again, all tissues are mixed. In the MSI column, zeros and ones correspond to MSI unstable and stab le, respetively. The pos and neg labels correspond to the feature being true or not, respetively.
The output of an ODOF analysis is a time series that contains statistical information about the association found between the drug and the feature. See for gdsctools.anova_results.ANOVAResults for more details.
If you want to repeat this analysis for all features for the drug 1047, you will need to know the feature names. This is stored in the following attribute:
gdsc.feature_names
The best is to do it in one go though since it will also fill the FDR correction column based on all associationa computed.
See also
4.3.2. One Drug All Features (ODAF)¶
Now that we have analysed one drug for one feature, we could repeat the analysis for all features. However, we provide a method that does exactly that for us (anova_one_drug()):
from gdsctools import ANOVA, ic50_test
gdsc = ANOVA(ic50_test)
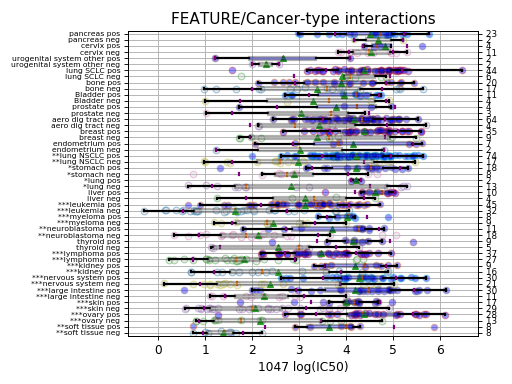
results = gdsc.anova_one_drug(999)
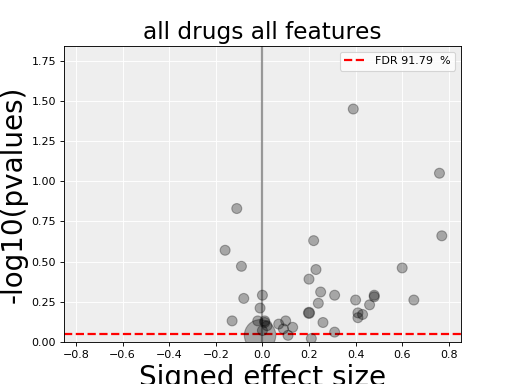
results.volcano()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
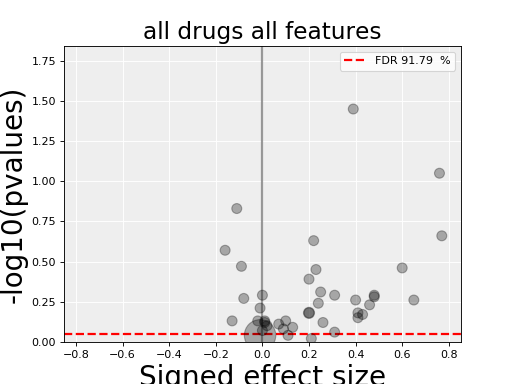
In a python shell, you can click on a dot to get more information.
Here, we have a different plot called a volcano plot provided in
the gdsctools.volcano module. Before explaining it, let us
understand the x and y-axis labels.
Each row in the dataframe produced by anova_one_drug() is made of a set of statistical metrics (look at the header results.df.columns). It includes a p-value (coming from the ANOVA analysis) and a signed effect size can also be computed as follows.
In the ANOVA analysis, the population of IC50s is split into positive and
negative sets (based on the genomic feature). The two sets are denoted 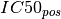 and
and 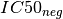 . Then, the signed effect size
. Then, the signed effect size 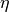 is computed as follows:
is computed as follows:
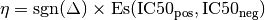
where
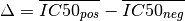
and 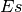 is the effect size function based on the Cohens metric (see
is the effect size function based on the Cohens metric (see
gdsctools.stats.cohens()).
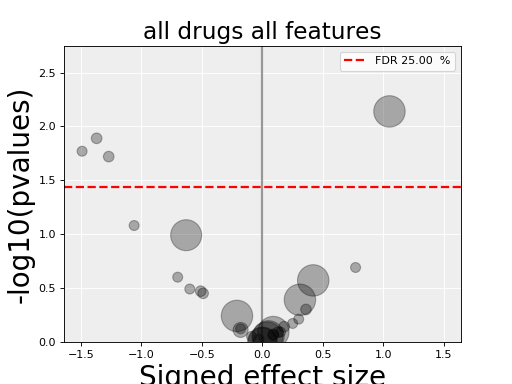
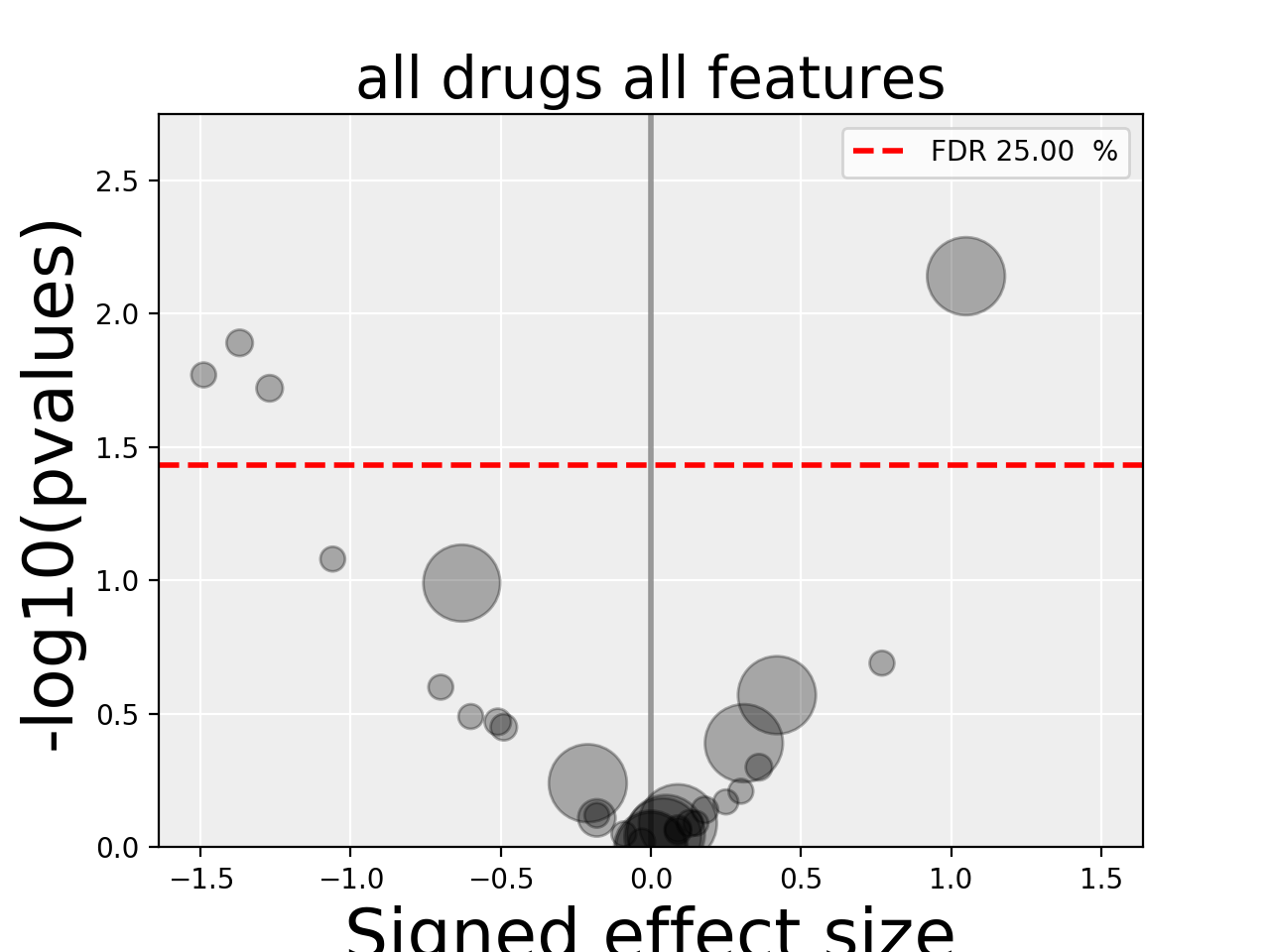
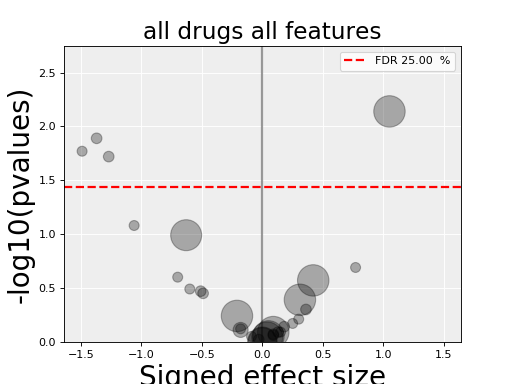
In the volcano plot, each drug vs genomic feature has a p-value. Due to the increasing number of possible tests, we have more chance to pick a significant hit by pure chance. Therefore, p-values are corrected using a multiple testing correction method (e.g., BH method). The column is labelled FDR. Significance of associations should therefore be based on the FDR rather than p-values. In the volcano plot, horizontal dashed lines (red) shows several FDR values and the values are shown in the right y-axis. Note, however that in this example there is no horizontal lines. Indeed, the default value of 25% is well above the limits of the figure telling us that there is no significant hits.
Note that the right y-axis (FDR) is inversed, so small FDRs are in the bottow and the max value of 100% should appear in the top.
Note
P-values reported by the ODOF method need to be
corrected using multiple testing correction. This is done
in the the ODAF and ADAF cases.
For more information, please see the
gdsctools.stats.MultipleTesting() description.
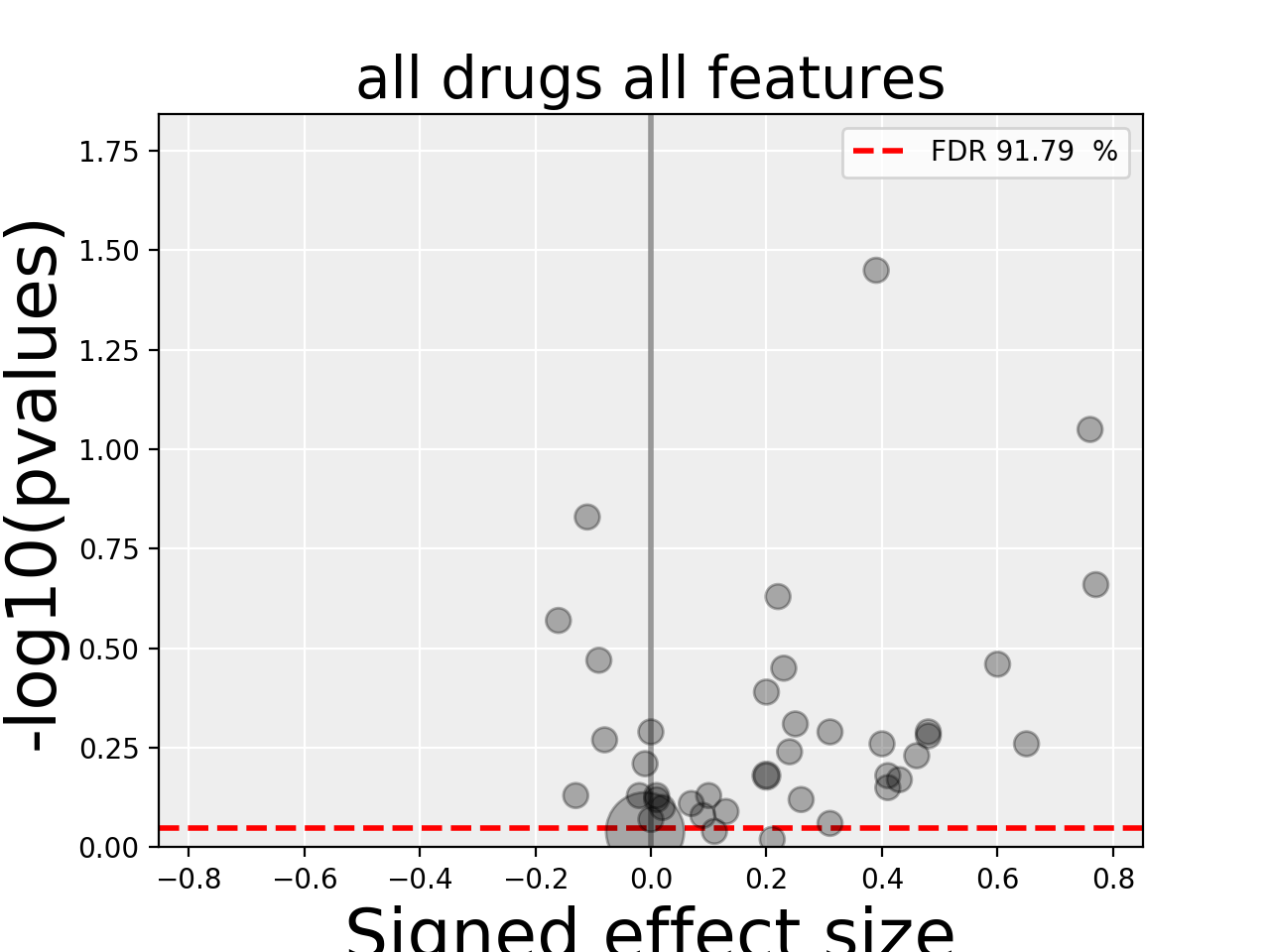
4.3.3. All Drug All Features (ADAF)¶
Here we compute the associations across all drugs and all features. In essence, it is the same analysis as the ODAF case but with more tests.
In order to reduce the computational time, in the following example,
we restrict the analysis to the breast tissue
using set_cancer_type() method. This would
therefore be a cancer-specific analysis. If all cell lines are kept, this is a PANCAN analysis. The information about tissue is stored in the genomic feature matrix in the column named TISSUE_FACTOR.
from gdsctools import ANOVA, ic50_test
gdsc = ANOVA(ic50_test)
gdsc.set_cancer_type('breast')
results = gdsc.anova_all()
results.volcano()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Warning
anova_all() may take a long time to run
(e.g., 10 minutes, 30 minutes) depending on the number of drugs
and features. We have a buffering in place. If you stop the analysis in the
middle, you can call again anova_all() method and previous
ODAF
analysis will be retrieved starting the analysis where you previously
stoped. If this is not what you want, you need to call
reset_buffer() method.
The volcano plot here is the same as in the previous section but with more data points. The output is the same as in the previous section with more associations.
4.4. Learn more¶
If you want to learn more, please follow one of those links:
- About the settings also covers how to set some parameters yourself.
- Creating HTML reports from the analysis: HTML report.
- Learn more about the input Data Format and Readers .
- How to reproduce these analysis presented here above using the Standalone application.
- Get more examples from IPython Notebooks.
- How to produce Data Packages and learn about their contents.