GDSCTools documentation¶
Current version: 1.0.1, Jan 09, 2018

| Citation: | Cokelaer et al. GDSCTools for mining pharmacogenomic interactions in cancer Bioinformatics, 2017, https://doi.org/10.1093/bioinformatics/btx744 |
|---|---|
| Note: | developed and tested for Python 2.7, 3.4, 3.5 |
| Note: | The GDSCTools libary works for Python 2.7 and 3.5 but the standalone pipeline to be ran on cluster works on Python 3.5 only |
| Contributions: | Please join https://github.com/CancerRxGene/gdsctools project |
| Documentation: | On ReadTheDocs |
| GitHub: | On github |
GDSCTools is a free open-source Python library dedicated to the study of drug responses in the context of the GDSC (Genomics of Drug Sensitivity in Cancer) project. The main developer is Thomas Cokelaer (Institut Pasteur), and it is a joint effort of the groups of Mathew Garnett (Sanger Institute) and Julio Saez-Rodriguez (RWTH Aachen & EMBL-EBI).
It contains utilities to find significant associations between drugs and genomic features (e.g., gene mutation) based on an ANOVA analysis. Other methods, such as multi-factorial linear models based on Elastic Net are also available. Besides, the library should also be useful for manipulating dedicated data sets such as IC50 (drug response) or MoBEM (genomic features) data structures. Hence, we hope that GDSCTools serves as basis for other scientists to develop further methods.
First Steps
Get started with GDSCTools
Examples
Visit our example gallery
The ANOVA analysis
Browse the full documentation
GDSCTools is written in Python. If you are a developer and/or knows already about the Python ecosystem and the pip command, just type the following command in a Terminal to install GDSCTools:
pip install gdsctools
add the option --upgrade to get the latest release. Conversely, if you are not
familiar with Python or the command above, please see the Installation section
for further details. Note also that we strongly recommend to use Anaconda to install dependencies (e.g., numpy, matplotlib); GDSCTools is available on bioconda channel:
conda install gdsctools.
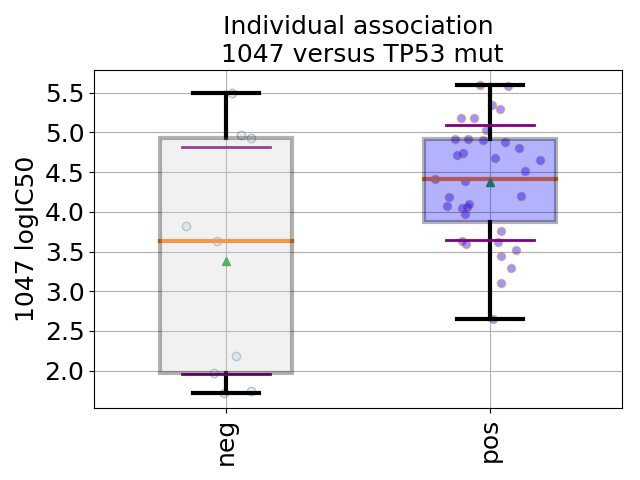
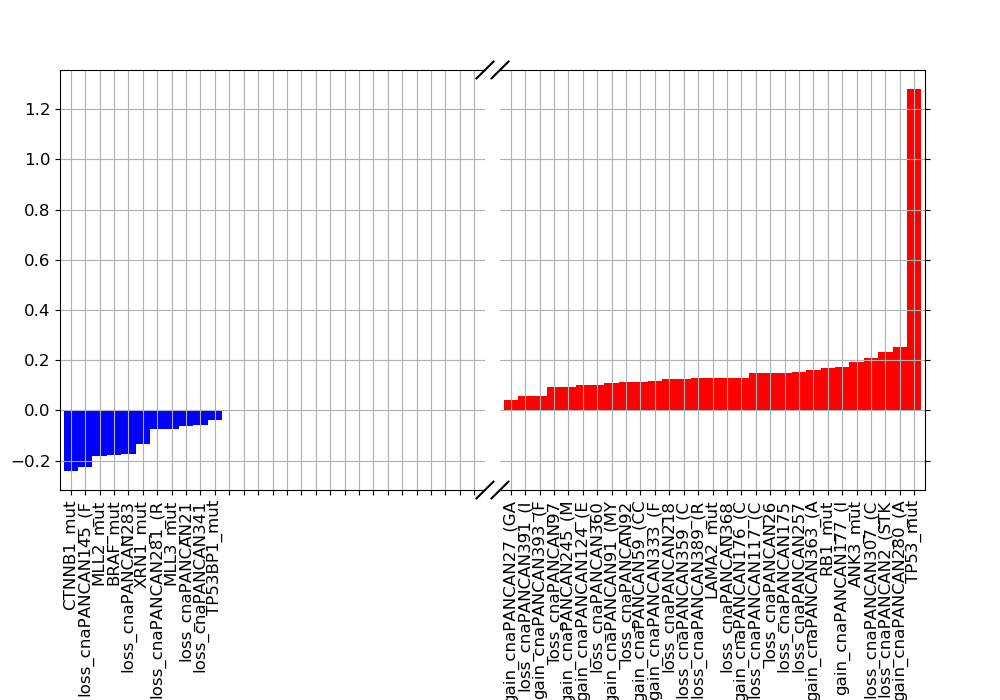
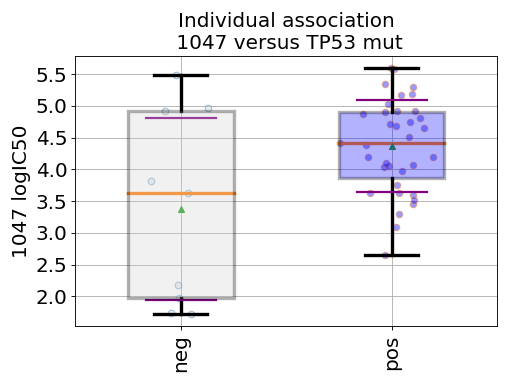
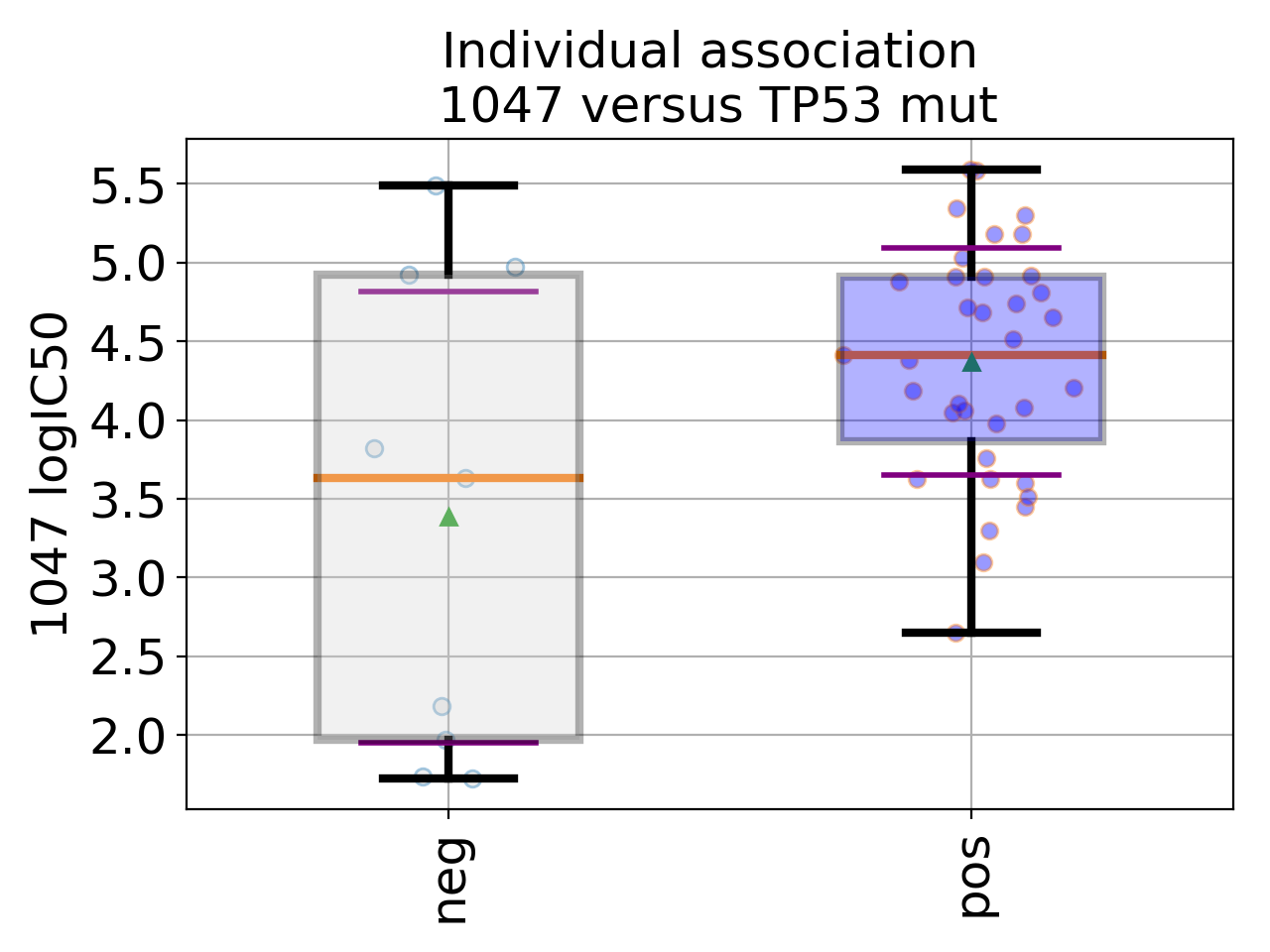
In the following example, we provide a short Python snippet that uses the GDSCTools library. You can either copy and paste the code in a file, and execute it or type the commands in an IPython shell. With this example we investigate the associations between the IC50 of a given drug (across 52 breast cancer cell lines) and a genomic feature (here, TP53 mutation). Drugs are refer to by a unique identifier (here 1047):
from gdsctools import ANOVA, ic50_test
gdsc = ANOVA(ic50_test)
gdsc.set_cancer_type('breast')
df = gdsc.anova_one_drug_one_feature(1047, 'TP53_mut', show=True)
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
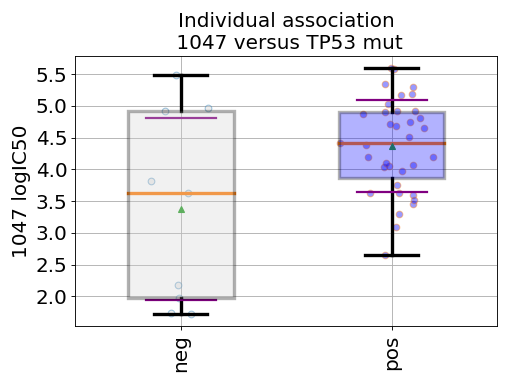
The df object returned in the last statement is a dataframe that contains information explained in Regression analysis section.
See also
For more examples and explanations, please visit the ANOVA analysis (introduction) section.
The previous example may be verbose with comments and warnings. You may set the verbose option to False and ignore warnings as follows:
import warnings
warnings.simplefilter("ignore","exceptions.Warning")
gdsc = ANOVA(ic50_test, verbose=False)
We will see more examples on how to use GDSCTools to perform more systematic studies. However, let us note that GDSCTools also provide a standalone application called gdsctools_anova, which can be used within a standard Terminal (same output as in the previous example):
gdsctools_anova --input-ic50 <ic50 filename> --drug 1047
--feature TP53_mut
If you want to have a go, please download this
IC50 example, which is required as an input.
Note that by default, GDSCTools loads a set of 50 genomic features and 1001 cell
lines but in general, you should provide your own genomic feature file (see Data Format and Readers). The default data set contains only a small set of genomic features and can be downloaded:
GenomicFeature example, and adapted to your needs.
See also
See Standalone application section for more details about the standalone application and the Data Format and Readers section to learn more about the expected input data formats.
Contents¶
- 1. Installation
- 2. Quick Start
- 3. Data Format and Readers
- 4. ANOVA analysis (introduction)
- 5. The ANOVA analysis in details
- 6. HTML report
- 7. Data Packages
- 8. OmniBEM Builder
- 9. Regression analysis
- 10. Notebooks
- 11. Standalone application
- 12. Gallery / Examples
- 13. Reproducibility
- 14. References
- 15. For developers
Issues¶
Please fill bug report in https://github.com/CancerRxGene/gdsctools/issues